인턴일기 - 31일차(RAG 성능평가 : 기술평가 + LLM 기반 평가)
2025. 6. 23. 23:25ㆍ데이터분석 인턴일기
오늘의 업무
RAG 기반 문서 검색/응답 시스템의 성능평가 수행
기술 지표 기반 평가와 LLM 응답 기반 평가를 병행
정답 라벨링 및 평가 기준 정립
오늘은 RAG(Retriveval-Augmented Generation) 구조에서 챗봇이 얼마나 정확하게 정보를 찾아내고, 의미있는 응답을 생성하는지를 정량적으로 분석해보는 실험을 진행했다.
실제 활용 가능한 정보를 주었는가?, 정확하게 정보를 찾아내서 의미적으로 유사한 응답을 생성하였는가? 를 평가해야 했기 때문에 생각이 많아졌다.
🧪 1. 기술 기반 성능평가 항목
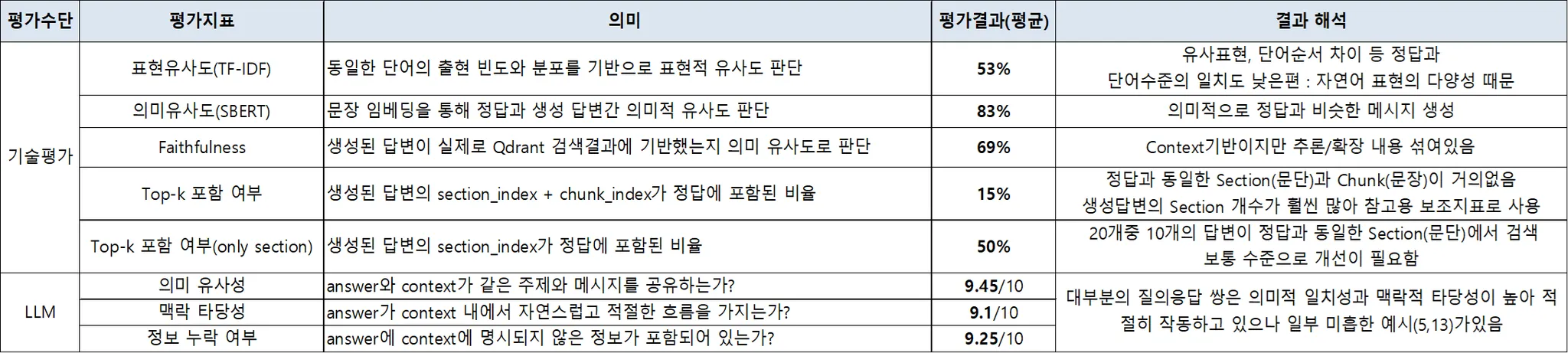
기계적으로 측정할 수 있는 기준을 바탕으로 여러 성능 지표를 정리했다.
다양한 임베딩 모델과 검색 옵션에 따라 수치 차이가 어떻게 나는지를 분석했다.
✅ 평가 항목
- TF-IDF 코사인 유사도: 단어 기반 유사도 측정
- Ko-SBERT 의미 유사도: 문장 의미 임베딩 기반 유사도
- Top-K 포함 여부 (Context Hit): 정답 문맥이 Top-K 안에 포함되었는가
- Faithfulness 점수: 생성된 답변이 실제 문맥에 기반했는가
이러한 항목은 주로 검색 단계에서의 정확도 측정에 활용되며, LLM 성능과는 별도로 분석된다.
🤖 2. LLM 기반 응답 평가 항목
LLM의 최종 응답을 기준으로 정답성과 맥락 적합성을 평가했다.
이는 단순히 문장을 잘 만드는가가 아니라, 문맥에 맞는 진짜 정보를 제공했는가를 따지는 평가다.
🧠 LLM 응답 평가 기준
- 의미 유사성: 질문에 대한 요지를 이해하고 있는가
- 맥락 타당성: 검색된 문맥과 연결된 내용인가
- 정보 누락 여부: 질문에 포함된 핵심 내용을 빠뜨리지는 않았는가
정답 라벨링 부분이 특히 힘들었다.
LLM 을 이용한 평가 부분은 챗봇에 쓰이지 않는 LLM을 써야한다고 해서 챗봇에 쓰이는 모델과는 다른 LLM 모델을 이용했다.
답을 생성할때 각각 LLM 어느 부분의 지식을 가지고 왔는지 명시하도록 하는것도 테스트에서 중요한 요소였다.
'데이터분석 인턴일기' 카테고리의 다른 글
| 인턴일기 - 33일차(DeepSeek vs Claude RAG 성능비교 & 토큰 계산실험) (2) | 2025.06.24 |
|---|---|
| 인턴일기 - 32일차(DeepSeek 기반 LLM 성능 비교 & RAG 평가 프롬프트 개선) (0) | 2025.06.23 |
| 인턴일기 - 30일차(RAG 성능평가 실험 & 의미 유사도 테스트) (0) | 2025.06.23 |
| 인턴일기 - 29일차(텍스트정제 -> 임베딩 -> Qdrant 업로드 구조 정비) (0) | 2025.06.23 |
| 인턴일기 - 28일차(임베딩 전 chunk size 조절 & 챗봇 테스트) (1) | 2025.06.23 |