2025. 6. 23. 23:11ㆍ데이터분석 인턴일기
오늘의 업무
텍스트 정제 -> 임베딩 -> Qdrant 업로드 -> 챗봇 테스트 기능을 코드로 분리
인증문서 기준 Rawdata 정리 및 우선순위 선정
오늘은 RAG 기반 챗봇 구축에 필요한 전처리 파이프라인을 모듈화 하고 구조적으로 정리하는 작업을 진행 했다.
특히 Rawdata 기준으로 인증별 문서의 우선순위를 정하고, 텍스트 전처리부터 임베딩 저장까지 전체 흐름을 정리하는데 집중했다.
📦 1. 인증별 Rawdata 정리 및 현황 시각화
우선 현재 가지고 있는 인증별 원문 데이터를 기준으로 rawdata 생성 현황을 정리했다.
각 인증 항목별로 문서 수, 작성 완료 여부, 검수 상태 등을 표시해 프로젝트의 전체 진행 상황을 한눈에 확인할 수 있게 했다.

🧠 2. 문서 우선순위 지정 및 정제 시작
단순히 데이터 양이 많은 것부터 처리하는 것이 아니라, LLM 챗봇에서 활용도가 높은 문서부터 처리할 수 있도록
각 문서 유형에 대해 우선순위를 정하고 정제 작업을 시작했다.

🛠 3. 텍스트 → 임베딩 → Qdrant 업로드 기능 분리
코드 구조를 다음과 같이 단계별로 분리해 재사용성과 유지보수성을 높였다.
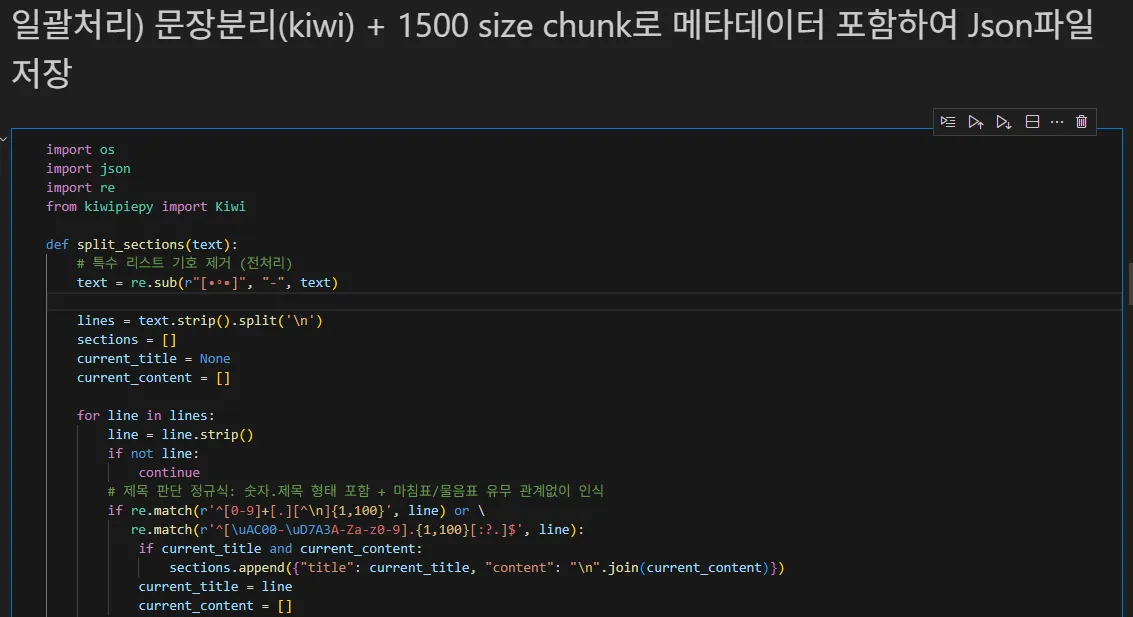
✂ 텍스트 정제 및 문장 분리 → JSON 저장
텍스트를 정제하고 문장 단위로 분리한 후, 문서명과 섹션명을 포함한 JSON 파일로 저장하는 구조를 만들었다.
📥 Qdrant 벡터 업로드
JSON 형태로 저장된 문서 chunk를 all-MiniLM-L12-v2 임베딩 후 Qdrant에 업로드하는 기능도 별도 함수로 분리했다.
메타데이터를 함께 포함해 향후 검색과 필터링에 활용할 수 있도록 구성했다.

💬 테스트용 프롬프트 구성
업로드된 벡터를 활용하여 실제 챗봇 응답을 테스트할 수 있는 프롬프트 구성 로직도 정리했다.
특정 인증 관련 질문을 던졌을 때, 올바른 정보를 찾아오는지를 검증하는 단계이다.

텍스트, 벡터화, 저장까지의 흐름을 기능별로 명확히 나눠서 실험과 디버깅이 훨씬 쉬워졌다는 것을 느꼈다.
'데이터분석 인턴일기' 카테고리의 다른 글
| 인턴일기 - 31일차(RAG 성능평가 : 기술평가 + LLM 기반 평가) (1) | 2025.06.23 |
|---|---|
| 인턴일기 - 30일차(RAG 성능평가 실험 & 의미 유사도 테스트) (0) | 2025.06.23 |
| 인턴일기 - 28일차(임베딩 전 chunk size 조절 & 챗봇 테스트) (1) | 2025.06.23 |
| 인턴일기 - 27일차(챗봇용 텍스트 임베딩 & 한국어 전처리) (0) | 2025.06.23 |
| 인턴일기 - 26일차(에러 로그 시스템 정비 & 함수 단위 핸들링) (0) | 2025.06.23 |