2025. 6. 23. 23:18ㆍ데이터분석 인턴일기
오늘의 업무
RAG(Retrieval-Agumented Generation) 구조에 대한 성능평가 실험
TF-IDF 및 Ko-SBERT 기반 유사도 비교
Top-K 문맥 검색 적중률 측정
오늘은 RAG시스템이 실제로 얼마나 의미있는 문맥을 검색하는지
그 성능을 객관적으로 평가하기위한 지표들을 설계하고 테스트했다.
단순히 모델이 잘동작하는 것이아니라 정확한 정보를 잘 찾아오는가를 측정했다.
🧮 1. 유사도 평가 – TF-IDF vs Ko-SBERT
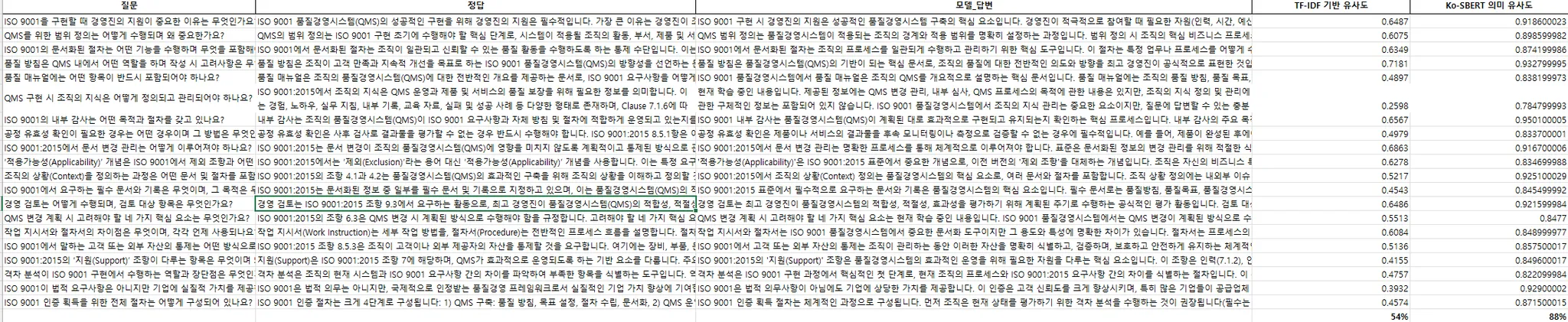
RAG 시스템의 검색 정확도를 비교하기 위해 두 가지 유사도 기준을 적용했다.
🔹 TF-IDF 기반 코사인 유사도
단어 기반으로 문장 간 유사도를 측정하는 방식으로, 표면적인 텍스트 일치를 잘 잡아낸다.
하지만 의미가 같아도 단어가 다르면 유사도가 낮게 측정되는 한계가 있다.
🔸 Ko-SBERT 기반 의미 유사도
문장 임베딩을 통해 문장의 의미적 유사성을 계산할 수 있다.
단어 표현이 달라도 맥락이 같으면 높은 유사도를 반환해 한국어 기반 LLM 시스템과 더 잘 어울리는 방식이다.
🎯 2. Top-K 문맥 적중률 평가 (Top-5 context hit)
검색 결과 중 상위 Top-5 문맥 중 실제 정답 문맥이 포함되었는지를 기준으로 성능을 평가했다.
이는 실제 RAG 구조에서 LLM이 활용하는 문맥의 정확성을 측정하는 가장 직관적인 지표다.
“정답 문장이 Top-5 내에 포함되었는가?”
그러나 생각보다 문맥 적중률이 굉장히 좋지 않아서 다시한번 적정한 평가인지 되돌아 봐야 할 것 같다.
오늘은 단순한 모델 응답이 아닌, 검색 정확도 자체를 수치로 측정하는 것의 중요성을 체감했다.
한국어 RAG를 구현할 경우 형태소 분석, 어순문제, 조사 단위 분리 등 고유의 언어 처리 문제가 존재하여, 그에 맞는 정제 방식과 평가지표도 별도로 고민해야한다는 것을 배웠다.
'데이터분석 인턴일기' 카테고리의 다른 글
| 인턴일기 - 32일차(DeepSeek 기반 LLM 성능 비교 & RAG 평가 프롬프트 개선) (0) | 2025.06.23 |
|---|---|
| 인턴일기 - 31일차(RAG 성능평가 : 기술평가 + LLM 기반 평가) (1) | 2025.06.23 |
| 인턴일기 - 29일차(텍스트정제 -> 임베딩 -> Qdrant 업로드 구조 정비) (0) | 2025.06.23 |
| 인턴일기 - 28일차(임베딩 전 chunk size 조절 & 챗봇 테스트) (1) | 2025.06.23 |
| 인턴일기 - 27일차(챗봇용 텍스트 임베딩 & 한국어 전처리) (0) | 2025.06.23 |