2025. 4. 7. 10:34ㆍ데이터분석 인턴일기
오늘의 업무
중복된 기사내용 삭제하는 코드 작성(모델생성?)
오늘은 어제 DB에 넣고간 데이터를 가지고와서 중복제거해주는 코드를 짜야한다!
예전에 해보고 말았던 한글형태소분석이라 다까먹어서 애좀먹었다.
(강의 재수강 해야겠다)
언제든 다시 볼수있다는 건 너무 좋은것 같다.
데이터 분석 직무를 시작하는 지금 교수님의 데이터분석 발언들이 내머리를 둥둥 떠다닌다.
라벨링지옥에 빠지게 될꺼에요...3D업종이죠...데이터과학에 정답은 없어요
무튼.. 아나콘다없이 해보는 파이썬.. 패키지 충돌이 일어날수도있다고 했는데
아직은 괜찮은것 같다. 멀쩡!
중복기사 정리 프로세스부터 정리해본다.
1. 형태소분석을한다(KoNLPy)
2. 형태소분석된 열로 TF-IDF벡터화
3. 코사인유사도계산
4. 유사도 0.6 기준으로 중복여부 판단
5. 중복제거된 데이터, 남은 데이터를 별도의 csv파일로 저장
1번 형태소분석을 하려면 KoNLPy 패키지를 설치해야하는데 그러러면 java가 필요하다고 한다.
시키는대로 java window버전을 깔아본다.
그다음에 환경변수 설정을 해야하는데 (이 환경변수 설정이 아주 중요하다.)
java를 설치한 폴더위치에서 환경변수를 설정해준다.
환경변수 설정이 중요한 이유!
* PATH 환경변수는 운영체제에서 프로그램을 찾는 경로 목록을 정의
* JAVA를 설치하면 javac(컴파일러), java(런타임실행기) 같은 명령어들이 bin 폴더안에 들어있는데 path에 bin 경로를 추가하지않으면 명령프롬프트나 터미널에서 java,javac 명령어를 실행해도 시스템이 찾을 수 없다.
* JAVA_HOME환경변수를 사용해서 JDK의 위치를 찾는다. (bin폴더를포함하지않는다)
*만약 JAVA_HOME의 값을 변경하면 다른 버전의 JDK로 전환이 가능하다.


JAVA를 모두 잘 설정했다!
근데 그래도 파이썬에서 JAVA를 찾지 못한다.ㅠㅠ
cd > Desktop 다음
pip install jpype1-1.5.2-cp312-cp312-win_amd64.whl 을 해서 설치를 해줘야하는데
pip 가 안된다

이때 tip.프롬프트작성하면서 tap버튼을 누르면 자동완성이된다.
시스템 경로에 한글이 있으면 잘 불러오지 못하는데
내컴은 저렇게 사용자명이 영문으로 미리 바꿔놔서 교육받을때 문제가없었지만
회사컴은 내 한글이름으로 되어있어서 그런것 같다.
근데 자바경로는 모두 영문인데...?
(팀장님이 파이썬 경로는 영문이아니라서 그렇다고 하신다...)
파이썬을 결국 두번 재설치했다.
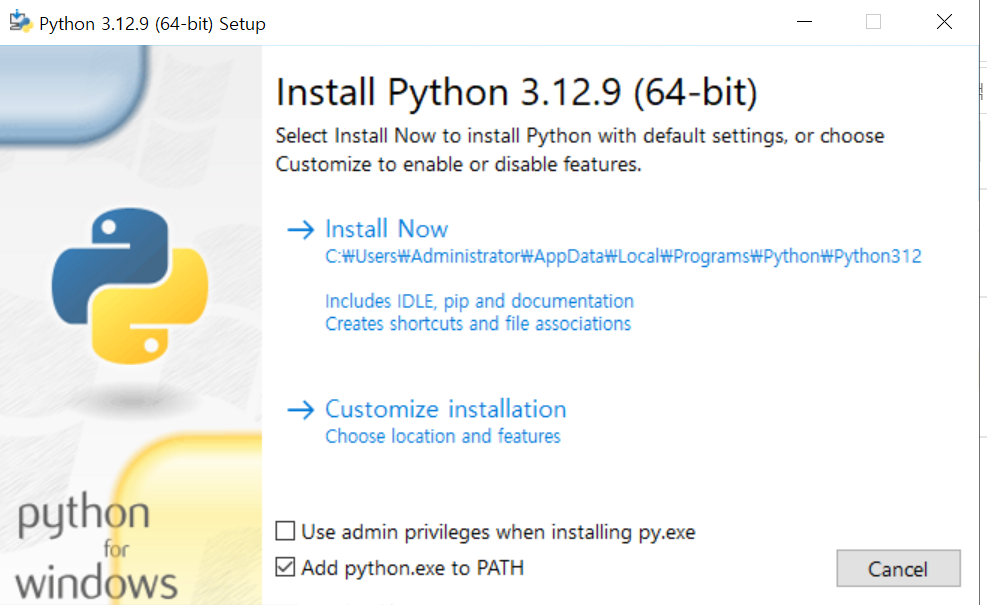
Add python.exe to PATH 를 꼭 체크해서 파이썬 경로를 환경변수 경로에 추가해야한다
환경변수와 경로의 중요성을 되새기는 시간이었다. ^ㅇ^
또 다른 회사에서 분명 또 깔게 될테니 다 적어놓는다! 어쨌든 이제 KoNLPy을 쓸수있게 되었다.
코사인유사도를 계산해본다.
# 형태소 분석기 초기화
okt = Okt()
# 형태소 분석 함수 정의 (명사, 동사, 형용사만 추출)
def tokenize(text):
tokens = okt.pos(text, stem=True) # 형태소 분석 및 어간 추출
words = [word for word, tag in tokens if tag in ['Noun', 'Verb', 'Adjective']]
return ' '.join(words)
# 데이터 읽기 (파일이름 수정 필요)
df = pd.read_csv('your_file.csv')
# 형태소 분석 적용
df['processed_description'] = df['description'].apply(tokenize)
# 저장할 폴더 생성
output_folder = "output" os.makedirs(output_folder, exist_ok=True)
# 저장할 데이터프레임 초기화
all_cleaned = pd.DataFrame()
all_removed = pd.DataFrame()
# 그룹별로 처리 threshold = 0.6 # 유사도로 판단할 기준값
max_features = 10000 # TF-IDF에서 사용할 최대 단어 수 제한
for keyword, group in df.groupby('keyword'): if len(group) <= 1:
# 데이터가 하나뿐인 경우는 그대로 추가
all_cleaned = pd.concat([all_cleaned, group]) continue
# TF-IDF 벡터화 (각 그룹별로 수행, 형태소 분석된 열을 사용)
vectorizer = TfidfVectorizer(max_features=max_features)
vectors = vectorizer.fit_transform(group['processed_description'])
# 코사인 유사도 계산
similarity_matrix = cosine_similarity(vectors)
# 중복 인덱스 찾기
drop_indices = set() for i in range(len(similarity_matrix)):
for j in range(i + 1, len(similarity_matrix)):
if similarity_matrix[i][j] >= threshold:
drop_indices.add(j)
결과를 확인했는데 그렇게 좋지 않았다. 왜일까?!
코사인 유사도를 비교할때 앞에서 이미 비교된 문장을 제외도해보고 포함도 해봤지만 성능이 그렇게 좋지 않은것 같다.
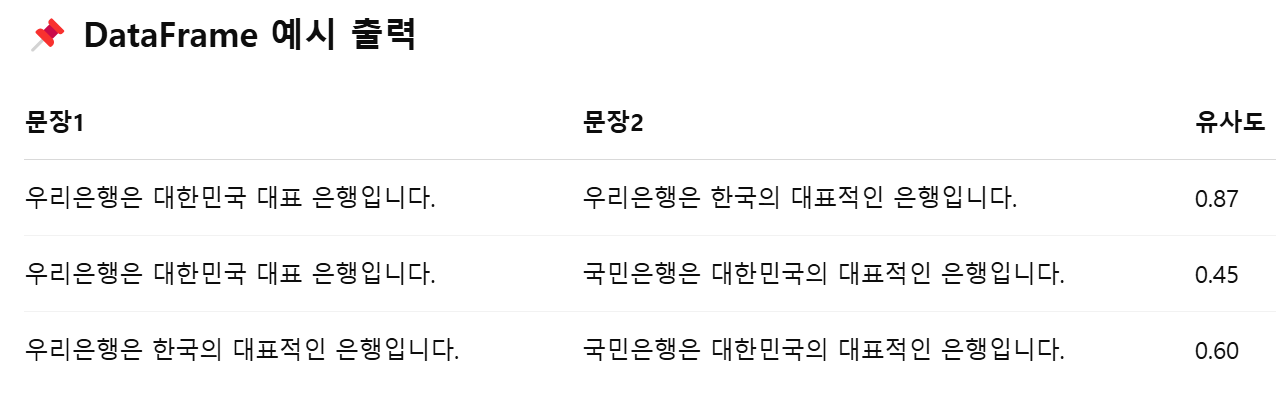
그래서 이유가 뭔지
다른 유사도는 뭐없는지 찾아보았다.
내가 비교하고자 하는건 뉴스데이터고 그중에서 API로 가져온 뉴스 기사의 일부 문장이 얼마나 비슷한지다.그리고 비슷한 정도에 따라서 중복기사로 분류한 후 삭제하는것이와 유사한 케이스에서는 자카드 유사도가 더 좋다는 글을 보았다.
자카드 유사도는 단어의 집합으로 유사도를 판단한다.

# 형태소 분석기 초기화
okt = Okt()
def fetch_articles(keyword, page): start = 1 if page == 1 else 101 # 페이지 1은 1~100, 페이지 2는 101~200
url = f"https://openapi.naver.com/v1/search/news.json?query={keyword}&display=100&start={start}" headers = { "X-Naver-Client-Id": client_id, "X-Naver-Client-Secret": client_secret }
try: response = requests.get(url, headers=headers) response.raise_for_status() # HTTP 에러 발생 시 예외 발생 result = response.json() items = result.get('items', []) return items except Exception as e: write_error_log(e) return []
def tokenize(text):
tokens = okt.pos(text, stem=True)
words = [word for word, tag in tokens if tag in ['Noun', 'Verb', 'Adjective']] return words
def jaccard_similarity(list1, list2):
set1 = set(list1)
set2 = set(list2)
intersection = len(set1.intersection(set2)) union = len(set1.union(set2)) if union == 0:
return 0 return intersection / union
지우고 남은 기사문장간의 유사도를 샘플로 한번 확인해보았다.


CSV파일로 저장해 사람의 눈으로(내눈) 검토할 예정이다.

'데이터분석 인턴일기' 카테고리의 다른 글
| 인턴일기 - 6일차(뉴스크롤링, 중복제거, 코드개선) (0) | 2025.04.10 |
|---|---|
| 인턴일기 - 5일차(유사도분석 결과검토, 중복제거 Flow 개선) (3) | 2025.04.07 |
| 인턴일기 - 3일차(코드 개선, postgre에 회사정보넣기) (0) | 2025.04.02 |
| 인턴일기 - 2일차(파이썬, postgresql utf-8 연결 에러) (0) | 2025.04.02 |
| 인턴 일기 - 1일차 (0) | 2025.04.02 |